
🎓 PhD in NLP / Software Developer
Email /
CV /
LinkedIn /
GitHub /
Scholar /
R-Gate /
Semantic /
Scopus /
WoS /
ORCID
Twitter /
Hugging Face /
Youtube /
bluesky /
Blog /
Instagram
AI
ABOUT
NEWS

|
Tap to quick filter Representative entries are highlighted. |
|
|
Research Fellow
Dec. 2023 - Present | UK, England, Bournemouth
|
||||||||||
|
|
Research Assistant
Dec. 2022 - Dec. 2023 | UK, England, Newcastle upon Tyne
|
||||||||||
|
|
Nicolay Rusnachenko Research Colloquium (Winter Semester 2025/2026) Online (Online Presentation) |
||||||||||
|
|
Nicolay Rusnachenko CSC8644 @ Newcastle University Urban Sciences Building (Newcastle University), Newcastle Upon Tyne, 11'th March, 2023 England, United Kingdom (UK) (Online Presentation) |
||||||||||

|
Nicolay Rusnachenko IEEE Standard Association (IEEE SA), Online 06-02-2026, No Expirity (Certificate) |
||||||||||

|
Nicolay Rusnachenko IEEE Standard Association (IEEE SA), Online 17-07-2025, 2 years (Certificate) |
||||||||||
|
Tong Wu, Huizhi Liang Nicolay Rusnachenko ACL 2026, San Diego, California, USA / SemEval-2026 Task 3 (DimABSA 2026) (Contest) We use bulk-chain for fast inference. |
||||||||||
|
Harshal Dharpure, Nicolay Rusnachenko ACL 2026, San Diego, California, USA / SemEval-2026 Task 3 (DimABSA 2026) (Contest) |
||||||||||

|
Mengxuan Sun, Nicolay Rusnachenko LREC-COLING 2026 / ArchEHR-QA 2026 Task 4 Competition (Contest) |
||||||||||
|
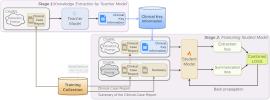
Nicolay Rusnachenko, Xiaoxiao Liu, Jian Chang, Jian Jun Zhang CLEF-2025 / BioASQ-2025 9-12 September 2025, Madrid, Spain (Oral Presentation) Proceeding of the earlier proposed MediExtract distil-tuning framework, which has been reforged to support decoder-based models (LLMs) with role-based prompt formation. The key contribution of the novel framework is its scalable potentials to other modalities. |
||||||||||
|
Nicolay Rusnachenko, James Franklin, Theophilus Akudjedu, Neel Doshi, Michael Board, Jian Chang, Jian Jun Zhang CASA-2025 and AniNex Workshop Offline, 02 June - 04 June 2025, Strasbourg, France (Poster Presentation) |
||||||||||

|
Natalia Loukachevitch, Lapanitsina Anna, Tkachenko Natalia, Mikhail Tikhomirov, Nicolay Rusnachenko The second competitions organized by DIALOGUE association. Online, 01 October - 15 November 2024 (Competitions) RuOpinionNE-2024 proceeds the past year RuSentNE-2023 that go further with: ↗️ annotation of other sources of opinion causes: entities, out-of-context object ( None), and
📏 evaluation of factual statements that support the extracted sentiment.
|
||||||||||
|
|
Nicolay Rusnachenko The 6'th Healthcare Summit hosted by JohnSnowLabs NLP Healthcare Summit, Online, 1-2 April 2025 (Online Presentation) |
||||||||||

|
Nicolay Rusnachenko IEEE Standard Association (IEEE SA), Online, 24-27 February 2025 (Training) |
||||||||||
|
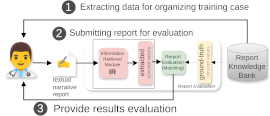
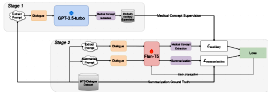
Xiaoxiao Liu, Mengqing Huang, Nicolay Rusnachenko, Julia Ive, Jian Chang, Jian Jun Zhang IEEE International Conference on Bioinformatics and Biomedicine (BIBM) Lisbon, Portugal, 3-6 Dec. 2024 (Oral Presentation) MediExtract Distillation Framework (MEDF) is a a hybrid teacher-student distillation process that leverages the power of LLMs in information capturing to enhance the performance of a smaller student model. |
||||||||||

|
Nicolay Rusnachenko (Framework) A hub of third-party providers and tutorials to help you instantly apply various NLP techniques. |
||||||||||
|
|
Nicolay Rusnachenko (Framework) A tiny Python no-string package for performing translation of a massive stream of texts with native support of pre-annotated fixed-spans that are invariant for translator. Powered by AREkit-pipelines. |
||||||||||
|
|
Nicolay Rusnachenko NCCA Research Seminar 13'th November 2024 Bournemouth University, Poole House, Lawrence Lecture Theatre, United Kingdom (Oral Presentation) In this talk, by saying reading in between the lines, we refer to performing such and Implicit IR that involves extraction of such information that is related to, i.e. ✍ ️author / 👩⚕️ patient / 🧑🦰 character etc. |
||||||||||

|
Nicolay Rusnachenko BFX'24 Bournemouth University 30'th October 2024 Hilton Bournemouth, United Kingdom (Project Presentation) We showcase the importance on NLP application for processing medical narratives of liver-related MRI/CT scan series, such as one mentioned in "Series Descriptions" of the DICOM metadata. The end-to-end concept advances were demonstrated as well. |
||||||||||

|
Nicolay Rusnachenko (Framework) A lightweight, no-strings-attached Chain-of-Thought framework for your LLM, ensuring reliable results for bulk input requests stored in CSV / JSONL / sqlite. It allows applying series of prompts formed into schema |
||||||||||

|
Nicolay Rusnachenko (Framework) A no-strings framework for Named Entity Recognition (NER) in large textual collection with third-party AI models via very accessible API. Powered by AREkit-pipelines. |
||||||||||
|
|
Nicolay Rusnachenko The 5'th summit hosted by JohnSnowLabs NLPSummit, Online, 24-26 September 2024 (Online Presentation)
/
related-paper /
code /
talk-details /
post /
twitter /
linkedin /
📙 colab-model /
📙 colab-experiments
/
The talk is devoted to application of Large Language Models (LLMs) for retrieving implicit information from non-structured texts via reasoning the result sentiment label. To enhance model reasoning capabilities 🧠, we adopt Chain-of-Thought technique and explore its proper adaptation in Sentiment Analysis task. |
||||||||||
|
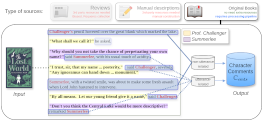
Nicolay Rusnachenko, Huizhi Liang The 10th International Conference on Machine Learning, Optimization, and Data Science September 22–25, 2024 Tuscany, Italy (Oral Presentation) This paper proposes the workflow of automatic profiling fictional character from literature novel books. The workflow is aimed at character personalities construction by solely rely on their comments in book: dialogue utterances and surrounding text, paragraphs. |
||||||||||
|
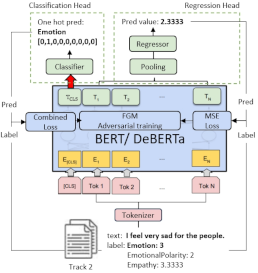
Huiyu Yang, Liting Huang, Tian Li, Nicolay Rusnachenko, Huizhi Liang 14th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA-2024) Co-located with ACL 2024, 11-16 August Bangkok, Thailand (Oral Presentation) (Contest) We propose a loss function which combines: (1) structured contrastive loss and (2) Pearson loss. For exploiting the related function in BERT optimization process, we propose "Adversarial Training with Fast Gradient Method (FGM)". To improve model generalization ability we exploit "mix-up" as a data augmentation technique to mix inputs with the labels in specific range. |
||||||||||
|
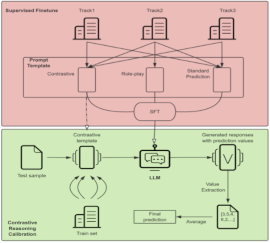
Tian Li, Nicolay Rusnachenko, Huizhi Liang 14th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA-2024) Co-located with ACL 2024, 11-16 August Bangkok, Thailand (Oral Presentation) (Contest) We adopt two-stage method SFT (🟥) + inference (🟩) as contrastive reasoning calibration (CRC). For the training, we enrich input samples: standard, role-play, contrastive. We concatenate the article and task content togerther in input to train model predict all track results (1,2,3). |
||||||||||
|
Nicolay Rusnachenko, Huizhi Liang The 18th International Workshop on Semantic Evaluation Co-located with NAACL 2024, June 16-21, 2024 Mexico City, Mexico (Contest)
paper /
/
slides /
arXiv /
twitter /
code-model /
🤗 models /
code-datasets /
codalab /
leaderboard /
📙 colab-model /
📙 colab-experiments
/
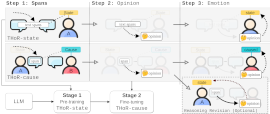
We fine-tune Flan-T5-base (250M) with the reforged THoR-ISA framework for Emotion Cause Extraction. Our final submission is 3'rd place by F1-proportional and 4-5'th by F1-strict which counts the emotion cause span borders. Our THOR-ECAC is publicly available. |
||||||||||
|
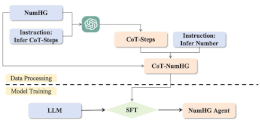
Junzhe Zhao, Yingxi Wang, Huizhi Liang, Nicolay Rusnachenko The 18th International Workshop on Semantic Evaluation Co-located with NAACL 2024, June 16-21, 2024 Mexico City, Mexico (Contest) We propose a two-phase SFT training strategy: (i) data-processing and (ii) model training. In (i) we combine CoT + knowledge-distillation concept (using GPT-3.5) + CoT steps for CoT-NumHG; this resource is then adopted in (ii) for the full-param SFT |
||||||||||
|
|
Nicolay Rusnachenko DataFest-2024, Online, 31 May 2024, (Oral Presentation) This is the Russian version of the talk devoted to application of Large Language Models (LLMs) for retrieving implicit information from non-structured texts via reasoning the result sentiment label. To enhance model reasoning capabilities 🧠, we adopt Chain-of-Thought technique and explore its proper adaptation in Sentiment Analysis task. |
||||||||||

|
Nicolay Rusnachenko MergeXR Studio Limited, 10 Dallow Road, Luton, United Kingdom 9-10'th May 2024 (Promotion and Project Presentation) Presented a multi-disciplinary research to transform the UK/global healthcare sector and allied training using digital technologies derived from the creative industries sector. In particular, the personal findings on Multimodal LLM-based system development and research to be conducted has been demonstrated in a form of the demo setups. |
||||||||||
|
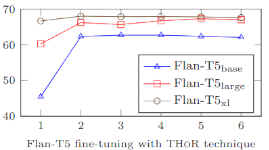
Nicolay Rusnachenko, Anton Golubev, Natalia Loukachevitch The 18th Lobachevskii Journal of Mathematics No.8 / LJoM-2024 Submitted on 16'th April 2024 (Journal Paper) We explore LLMs reasoning capabilities in Targeted Sentiment Analysis task. In particular we assess LLM models in two modes: (i) zero-shot-learning (ZSL) (ii) fine-tuning with prompt and CoT THoR proposed at ACL-2023. The fine-tuned Flan-T5-xl outperforms the prior top submission at RuSentNE-2023. |
||||||||||
|
|
Nicolay Rusnachenko, Huizhi Liang, Maxim Kolomeets, Lei Shi 46th European Conference on Information Retrieval, 24th-28th March, 2024 Glasgow, Scotland (Demonstration Paper, Oral Presentation, Offline) Old Pre-release ARElight-0.22.0 related materials:
slides /
/
AREkit-based application for a granular view onto sentiments between entities for large document collections, including books, mass-media, Twitter/X, and more. See our online demo |
||||||||||
|
|
Nicolay Rusnachenko Glasgow IR Research Group, Sir Alwyn Williams Building, Glasgow, G12 8QN, 22 January 2024 Scotland, United Kingdom (UK) (Oral Presentation) Unlike to the similar talks in past, in this one we overview the capabilities the most-recent instructive Large Language Models (LLM). This list includes: Mistral, Mixtral-7B, Flan-T5, Microsoft-Phi2, LLama2, etc. We also cover advances of LLM-fine tuning by exploiting Chain-of-Thought techniques to get the most out of the LLM capabilities. |
||||||||||

|
Harry Peach, Nicolay Rusnachenko, Mayank Baraskar, Huizhi Liang, 14th International Conference on Innovations in Bio-Inspired Computing and Applications (IBICA-2023), December 14-15, 2023 Kochi, India (Oral Presentation, Online) |
||||||||||
|
|
Nicolay Rusnachenko, Huizhi Liang, Maxim Kolomeets, Lei Shi Scalalable Research Group Seminars Urban Sciences Building (Newcastle University), Newcastle Upon Tyne, 11'th March, 2023 England, United Kingdom (UK) (Oral Presentation) AREkit-based application for a granular view onto sentiments between entities in a mass-media texts written in Russian. Project presentation. |
||||||||||
|
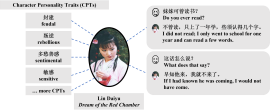
Junzhe Zhao, Huizhi Liang, Nicolay Rusnachenko Proceedings of the The 22nd IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology October 26-29, 2023 Venice, Italy (Oral Presentation, Online) We propose an automated system that uses character dialogues from literary works. We used the Chinese classic, Dream of the Red Chamber. Our system efficiently extracts dialogues and personality traits from the book, creates a personality map for each character, generates responses that reflect these traits. |
||||||||||

|
Nicolay Rusnachenko (Personal Report) This report represent a study of how well the annotated relations in NEREL could be predicted by ChatGPT-3.5. |
||||||||||
|
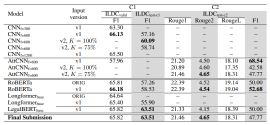
Nicolay Rusnachenko, Thanet Markchom, Huizhi Liang Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) Association for Computational Linguistics (ACL) Toronto, Canada (Contest) |
||||||||||
|
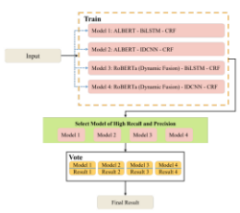
Junzhe Zhao, Yingxi Wang, Nicolay Rusnachenko, Huizhi Liang Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) Association for Computational Linguistics (ACL) Toronto, Canada (Contest) Application of the transformer-based model for the named entity recognition task in legal texts. |
||||||||||

|
Anton Golubev, Nicolay Rusnachenko, Natalia Loukachevitch Dialogue-2023, Codalab platform, 2023 (Competitions) Participants are offered the task of extracting sentiments of three classes (neg, pos, neutral) from news texts in relation to pre-marked entities such as PERSON, ORG, PROFESSION, COUNTRY, NATIONALITY within a separate sentence. |
||||||||||
|
Nicolay Rusnachenko, The Anh Le, Ngoc Diep Nguyen Proceedings of the Artificial Intelligence and Natural Language Conference (AINL) / Journal of Mathematical Sciences (Springer Nature) 20-22'th April, 2023 Yerevan, Armenia (Oral Presentation, Online) A first LongT5-based model pre-trained on a large amount of unlabeled Vietnamese texts and fine-tuned within the manually summarized texts from ViMS and VMDS and VLSP2022 collections |
||||||||||

|
Nicolay Rusnachenko, Andrew Johnson, Al-Amin Bashir Bugaje, Lingyi Yang, Tai-Ying Lee, Mohammad Matin Saddiqi, Mansi Mungee (PI) The Catalyst (Newcastle University), Newcastle Upon Tyne, 21-24'th March, 2023 England, United Kingdom (UK) (Oral Presentation) Taking a facilitator Role in the The Rivers Trust project. The Rivers Trust company leads the Catchment Systems Thinking Cooperative (CaSTCo) project, which has been set up to provide a national framework for sharing water environment data across a range of stakeholders. To the best of our personal knowledge we were the first who experiment with the Graph Neural Networks application (GNN) for water quality assessment. |
||||||||||
|
|
Nicolay Rusnachenko Scalalable Research Group Seminars Urban Sciences Building (Newcastle University), Newcastle Upon Tyne, 11'th March, 2023 England, United Kingdom (UK) (Oral Presentation)
slides
/
In this talk we cover the advances of machine-learning approaches in sentiment analysis of large mass-media documents. Extends talk at Wolfson College (Oxford) with the detailed description of long-input transformers, RLHF training overview. |
||||||||||
|
|
Nicolay Rusnachenko The Alan Turing Institute, London, 3'rd March, 2023 England, United Kingdom (UK) (Oral Presentation) / (Impromptu) / (Skimming Session)
slides /
/
|
||||||||||
|
|
Nicolay Rusnachenko OxfordXML, OxfordTalks Wolfson College, University of Oxford, 10'th February, 2023 Oxford, England, United Kingdom (UK) (Oral Presentation) In this talk we cover the advances of machine-learning approaches in sentiment analysis of large mass-media documents. We provide both evolution of the task over time including a survey of task-oriented models starting from the conventional linear classification approaches to the applications findings of the recently announced ChatGPT model. |
||||||||||
|
|
Nicolay Rusnachenko (Github Repository)
code
/
|
||||||||||
|
|
Nicolay Rusnachenko (Github Repository) Low Resource Context Relation Sampler for contexts with relations for fact-checking and fine-tuning your LLM models, powered by AREkit |
||||||||||

|
Nicolay Rusnachenko School of Informatics, Newcastle University, 9'th December, 2022 Newcastle Upon Tyne, England, United Kingdom (UK) (Oral Presentation)
slides
/
|
||||||||||

|
Nicolay Rusnachenko Marketing Trends and AI (DIFC Innovation HUB, Open Stage, 17'th August, 2022 (Presentation)
slides /
certificate
/
|
||||||||||

|
Nicolay Rusnachenko (Framework) Document level Attitude and Relation Extraction toolkit (AREkit) for sampling mass-media news into datasets for your ML-model training and evaluation |
||||||||||
|
|
|||||||||||
|
|
Nicolay Rusnachenko DataFest-2022 3.0, Online, 18'th June, 2022 (Presentation) AREkit-based application for a granular view onto sentiments between entities in a mass-media texts written in Russian. Project presentation. |
||||||||||
|
|
Research Assistant
Moscow State University · Indirect Contract Jun 2022 - Nov 2022 · 6 mos Moscow, Moscow City, Russia · Remote
|
||||||||||

|
Nicolay Rusnachenko Bauman Moscow State Technical University, Moscow, 28'th April, 2022 Published by High Attestation Comission (Thesis Defence)
cert-uk /
cert-ru /
thesis-ru /
synopsis /
video-ru /
slides-ru /
patent-ru /
HAC-ru /
task-paper /
styles /
leaderboard
/
We propose distant-supervision approach for mass-media annotation, based on RuSentiFrames knowledge-base. We built and propose RuAttitudes collection for Sentiment Attitude Extraction task and adopt it for neural-networks training process, including BERT-based models. |
||||||||||
|
|
Research Assistant
Nov 2017 - Dec 2017 · 2 mos | Charles Sturt University · Remote
|
||||||||||
|
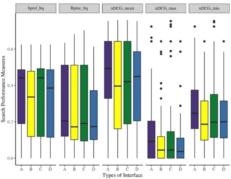
Ying-Hsang Liu, Paul Thomas, Tom Gedeon, Nicolay Rusnachenko ACM SIGIR Conference on Human Information Interaction and Retrieval, March 2022 Published by ACM ** Personal contribution were related to evaluation section and funded by Charles-Sturt-University, Australia (November 2017). See report for greater details. (Online Presentation) For Biomedical domain. We investigate: (1) which search interface elements searchers are look at when searching for docs to answer complex questions, and (2) relationship between individual differences and the interface elements which users are looked at. |
||||||||||
|
Nicolay Rusnachenko Proceedings of the Institute for System Programming of the RAS (Proceedings of ISP RAS), vol.33 Russia, Moscow, August 9'th, 2021 (Journal Paper) This lecture is devoted to the works that were done within last 4 years, which is related sentiment attitude extraction task. |
||||||||||
|
|
Nicolay Rusnachenko Introduction to Humanistic Informatics course Denmark, Odense, November 26'th, 2020 (Online Lecture)
/
slides
/
This lecture is devoted to the works that were done within the past 4 years, which is related sentiment attitude extraction task. |
||||||||||
|
|
|||||||||||
|
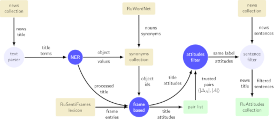
Nicolay Rusnachenko, Natalia Loukachevitch The 10th International Conference on Web Intelligence, Mining and Semantics (WIMS 2020), June 30-July 3 (arXiv:2006.13730) France, Biarritz, 2020 (Oral Presentation) Application of Distant Supervision in model training process results in a weight distribution biasing: frames in between subject and object of attitude got more weight values; the latter reflects the pattern of frame-based approach, utilized in RuAttitudes collection development. |
||||||||||
|
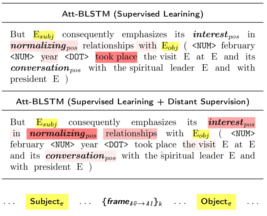
Nicolay Rusnachenko, Natalia Loukachevitch Proceedings of the 25th International Conference on Natural Language and Information Systems NLDB 2020. Lecture Notes in Computer Science, vol 12089. Springer, Cham (arXiv:2006.11605) Germany, Saarbrücken, 2020 (Oral Presentation) |
||||||||||
|
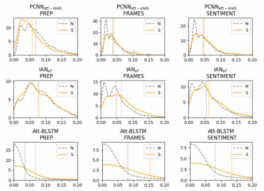
Natalia Loukachevitch, Nicolay Rusnachenko Proceedings of International Conference on Computational Linguistics and Intellectual Technologies Dialogue-2020 (arXiv:2006.10973) Russia, Moscow, 2020 (Oral Presentation) Provides a description of the developed RuSentiFrames lexicon with the related application for attitude extraction |
||||||||||

|
Natalia Loukachevitch, Nicolay Rusnachenko Conversations Conference Moscow, Loft Hall, 26'th November, 2019 (Oral Presentation by supervisor) |
||||||||||

|
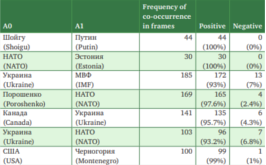
Natalia Loukachevitch, Karnaukhova V.A., Nicolay Rusnachenko Tatarstan Academy of Sciences, 2018 (Plenary) Pages: 169-179. The paper describes the task of automatic extraction of attitudes between the subjects mentioned in the text, as well as their connection with the implicit expression of the author's attitude to these subjects. A RuSentiFrames vocabulary is presented, in which the basic attitudes associated of Russian predicate words are described. |
||||||||||
|
|
Nicolay Rusnachenko (Presentation) cnn-example Lecture extra materials (English): |
||||||||||
|
|
Nicolay Rusnachenko, Natalia Loukachevitch, Elena Tutubalina First Athens Natural Language Processing Summer School Greece, Athens, September 18-26, 2019 (Poster Presentation) |
||||||||||
|
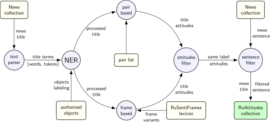
Nicolay Rusnachenko, Natalia Loukachevitch, Elena Tutubalina Proceedings of Recent Advances in Natural Language Processing Conference Bulgaria, Varna, 2019 (Poster Presentation) First time application of automatic attitudes extraction from raw news, based on news title presentation simplicity. |
||||||||||
|
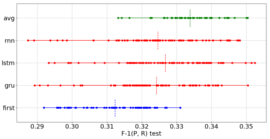
Nicolay Rusnachenko, Natalia Loukachevitch International Conference on Data Analytics and Management in Data Intensive Domains, Springer, 2018 Utilizing a set of sentence level attitudes with related metrics to perform a sentiment prediction. As for input of neural network based models, in prior works all the models deals with an attitudes limited by a single sentence. |
||||||||||
|
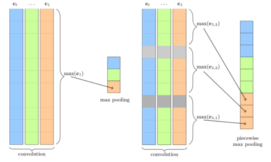
Nicolay Rusnachenko, Natalia Loukachevitch DAMDID-2018, CEUR Workshop Proceedings (ceur-ws.org) Russia, Moscow (MSU), 2018 (Oral Presentation), (Poster Presentation) An application of CNN based architecture (adapted for relation extraction) towards sentiment attitudes extraction task. |
||||||||||
|
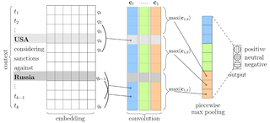
Nicolay Rusnachenko, Natalia Loukachevitch EPiC Series in Language and Linguistics 4, 1-10, 2019 An application of CNN based architecture (adapted for relation extraction) towards sentiment attitudes extraction task. Presented at Third Workshop "Computational linguistics and language science" (CCLS-2018), HSE, Moscow. |
||||||||||
|
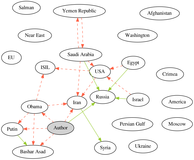
Natalia Loukachevitch, Nicolay Rusnachenko Proceedings of International Conference on Computational Linguistics and Intellectual Technologies Dialogue-2018 (arXiv:1808.08932) Russia, Moscow, 2018 (Oral Presentation) The first approach, i.e introduction of sentiment attitudes extraction task. Includes developed dataset with related experiments. |
||||||||||
|
|
Nicolay Rusnachenko, Natalia Loukachevitch International Conference on Text, Speech, and Dialogue (TSD) Czech Republic, Brno, 2018 (Oral Presentation) Introduction of sentiment attitudes extraction task. Includes developed RuSentRel with related experiments. |
||||||||||
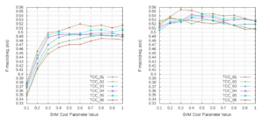
|
Nicolay Rusnachenko, Natalia Loukachevitch Artificial Intelligence and decision making (AIDM) journal, ISSN 2071-8594, 2017 (Best Student Paper Award at DIALOGUE-2016), (Poster Presentation) Provides details on lexicon development using twitter messages (related works [pmi], [dev], [sota]). Sentiment classification of user reviews using SVM. Master degree paper. |
||||||||||
|
|
Russia, Kazan, Kazan Federal University, 2018 (Poster Presentation) poster / paper / certificate / Russia, Saratov, SGU, 2016 Russia, Yekaterinburg, 2017 (Poster Presentation) |
||||||||||
|
|
.NET Software Developer
May 2016 - Dec. 2021 | Russia, Moscow
|