OHIF Import Measurements
The most relevant question raised in OHIF issues: https://github.com/OHIF/Viewers/issues/1800 Version 3.10.2
The most relevant question raised in OHIF issues: https://github.com/OHIF/Viewers/issues/1800 Version 3.10.2
🖼️ Unexpected traveling plan from Bolton to London: 1-2 Initial Route ⚫, but I took 3-4 🔴
Manchester Picadilly station represents one of the larges hub that connects South-West UK county.
Once you calling Manchester, no matter coach or train, you instantly becoming aware of it.
I used to callig that place for a long time, and it used to be journeys from far away: Newcastle Upon Tyne, and so far London (Euston train station) in this list.
However, there is a known psychological effect that finds manipulative applications in certain industries and involves repretitive series of actions with the same outcome.
Something that you’re doing quite often through the same path makes you a biased person in the particular domain area.
This is what happened and you may find yourself the same way …
Picture: Observation wheel of the new spot 🎡 or such an adventure traits?
When contranct is about to over or any other circumstaces sings to its termination, it becomes a time of personal iterest in eligibility of your further rights to work and stay in country. In some cases it might be just a simple switch to another position, but in others causes to issue a new VISA.
Sampling of the contexts with mentioned sentiment relations in it has become even simple to use rather it was before!
So far we work hard on the following features that make the application of this process as well as the application of the obtained results even more handy.
Here is the upcoming features and changes in AREkit-ss 0.24.0:
![]()
Let me share a quick summary and update on misalignment between LLM reasoning and manually annotated relations in mass media-news.

We are happy to announce the AREkit version 21.1.
In this post we cover the most imporant changes were done since the prior release. The complete and large list of the updates could be found on the release page.
Calculation of the derivatives plays a significant role in neural networks tuning.
The computational effectivenes is very crusial considering a large models and ability to train them.
Besides the CPU and one of the most common option for calculations, recent advances finds a significant application of GPU and TPUs
mostly because of a potentially greater performance vs. the central processing unit.
Obvioulsy, such features won’t be available without a special software support, required for networks compilation
towards the targeted processing unit.

In this tutorial we provide a list of steps required to prepare samples with text opinions for BERT language model.

This short post illustrates implementation of the base entity formatter. Entity formatter is requred for formatting values of mentioned named entities, masking them.

In this tutorial we provide a list of steps required to prepare samples with text opinions for neural networks like convolutional or recurrent one.


Besides the text contents processing, retrieving information and annotating inner objects in texts,
in case of Machine Learning models it is also required to manage data subsets.
In other words, there is a need to provide rules on how the series of documents is expected to be grouped in subsets.
For example, we may declare subsets for: Training, Testing, Validating, etc.
This post represents an AREkit tutorial devoted to Folding as a common type and the related concept on how data
separation might be described and passed into other pipelines required so.

In this post we are focusing on the relations extraction between a couple mentioned named entities in text.
Speaking precisely, we consider sentiment connections between mentioned named entities in text, i.e. positive or negative (and additionally neutral)
In order to automatically extract relations of such type, it is necessary to provide their markup in texts first, –
an algorithm, which allows us to extract text parts with potential connections between mentioned named entities.
The result markup could be then used for samples generation – data, which is requred from Machine Learning model training, inferring, testing and so on.

In AREkit-0.22.1,
we provide BaseTextParser which assumes to apply a series of text processing items, organized in a form of the PipelineItem’s,
in order to modify the text contents with the annotated objects in it.
The common class which is related to performing transformation from the original News towards the processed one is a BaseTextParser, which receives
a pipeline of the annotations expected to be applied towards a news text:

Source for annotation usually represent a raw text or provided with the bunch of annotations. The one of the most convinient way for creating and collaborative annotation ediding in Relation Extraction is a BRAT toolset. Besides the nice rendering and clear visualization of the all relations in text, it provides a web-based editor and ability to export the annotated data. However, the exported data is not prepared for most ML-based relation extraction models since it provides all the possible annotations for a single document. In order to simplify and structurize the contents onto text parts with the particular and fixed amount of annotations in it, in this post we propose the AREkit toolset and cover the API which provides an opportunity to bind your custom collection, based on BRAT annotation.
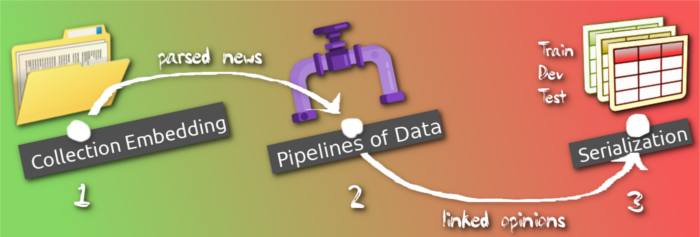
We are finally ready to annonce the workflow of data-processing organization in AREkit for sampling laa….aaarge collection of documents!
Here, the Laa....aarge denotes that the whole workflow could be treated as iterator of document collection.
At every time step we manage information about only a single document of the whole collection which allows us to avoid out-of-memory exceptions.

In this post we apply fine-tuned model for inferring sentiment relations from Mass-Media texts.

Figure: Results of an automatic sentiment relation extraction between mentioned named entities from Mass-Media Texts written in Russian. Visualized with BRAT Rapid Annotation Tool.
Sentiment attitude extraction [6] – is a sentiment analysis subtask, in which attitude corresponds to the text position conveyed by Subject towards other Object mentioned in text such as: entities, events, etc.
In this post we focused on the sentiment relation extraction between mentioned named entities in text, based on sampled contexts of Mass-Media news written in Russian. In terms of sentiments, we focused on two-scale sentiment analysis problem and consider: positive and negative attitudes. Samples were generated by AREkit and then utilized for BERT classification model training by means of DeepPavlov framework.
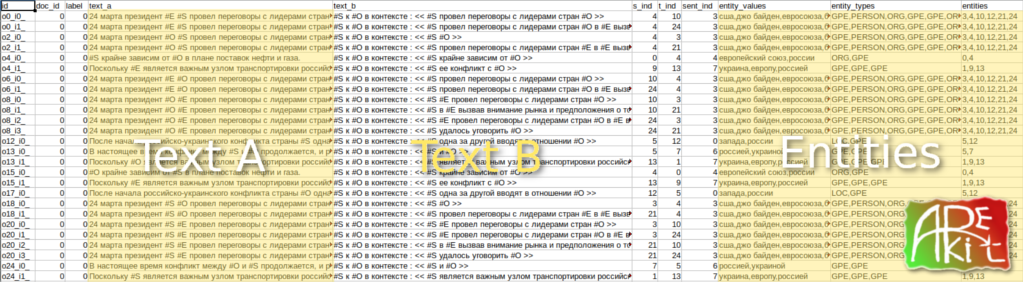
Automatic processing of a large documents requires a deep text understanding, including connections between objects extraction. In terms of the latter and such domain as Sentiment Analysis, capturing the sentiments between objects (relations) gives a potential for further analysis, built of top of the sentiment connections:
![]()
During the last few years the importance of a quick transformer tunnings for downstream tasks become even more demanded. Since such pretrained states might be treated as few shot learners makes them even more attractive for low resource domain tasks.
Earlier announced awesome list of sentiment analysis papers has been enlarged with reced advances in more time-effective tunning techniques:
In a nutshell, we my tunning extra token embeddings (p-tuning), or design input prompts (AutoPrompt) in order to adopt model for downstream tasks by keeping model state frozen.
Checkout the Awesome Sentiment Attitude Extraction List for a greater details.